 美国VPS_搬瓦工CN2 GIA VPS
美国VPS_搬瓦工CN2 GIA VPS
总体意思是
我提供一个记事本 里面一行一个词
您去百度搜索判断 低于1000的收录的 就可以判断是屏蔽词 就删除
怎么一个。。
有能做的 报价么? Q 12八7890
200-已接。谢谢各位
山东网友:点我头像下面联系
西藏网友:太JB简单了,自己写不好么
福建网友:QQ多少啊 我加你。你做下来多少钱
新疆网友:
下个插件,写个文件读取就可以了吧
湖北网友:也可以联系我
河北网友:就是不会这些高深的啊。大佬。有没有那种简单的。
湖南网友:不是大佬。。但这个确实是很简单的东西,稍微学一下,一天之内就能写完了
云南网友:
- import requests
- from bs4 import BeautifulSoup
- import re
- target = ‘https://www.baidu.com/s?ie=UTF-8&wd=’
- word = ‘loc’
- headers = {
- ‘Host’: ‘www.baidu.com’,
- ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36’,
- ‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3’,
- ‘Referer’: ‘https://www.baidu.com/’,
- ‘Accept-Encoding’: ‘gzip, deflate, br’,
- ‘Accept-Language’: ‘zh-CN,zh;q=0.9’,
- # ‘Cookie’: ‘刚发现自己浏览器登了百度帐号,cookie中可能有帐号信息,这里就先删除了,也不知道百度反爬判断cookie不,需要的话自己复制一个放在这里就行了’
- }
- req = requests.get(url=target+word, headers=headers)
- req.encoding = ‘utf-8’
- html = req.text
- bs = BeautifulSoup(html)
- span_tag_bs = bs.find_all(‘span’, class_="nums_text")
- num_text = span_tag_bs[0].text
- num_str = re.sub(‘\D’,”,num_text)
- num = int(num_str)
- if num < 1000:
- print(word+"是一个屏蔽词")
- else:
- print(word+"不是屏蔽词,有"+num_str+"个搜索结果")
复制代码word是loc时的结果
- loc不是屏蔽词,有29700000个搜索结果
复制代码刚刚随手写的,有点乱,能用就行
把word改成从文件中读取就满足楼主的要求了
吉林网友:我的天啊 随手一些 搞定了。。
不过我是垃圾,不会。。
接单的30分钟做好了。现在让他教我。。
楼上的哥哥,我。。。代码 我不知道怎么用。。。555
你不懂垃圾的痛苦
宁夏网友:我的天啊 随手一些 搞定了。。
不过我是垃圾,不会。。
接单的30分钟做好了。现在让他教我。。
楼上的哥哥,我。。。代码 我不知道怎么用。。。555
你不懂垃圾的痛苦
未经允许不得转载:美国VPS_搬瓦工CN2 GIA VPS » 找人写个PY。判断是否是百度的屏蔽词。
 腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程
腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程 亏了,刚才退款了一个greencloud日本
亏了,刚才退款了一个greencloud日本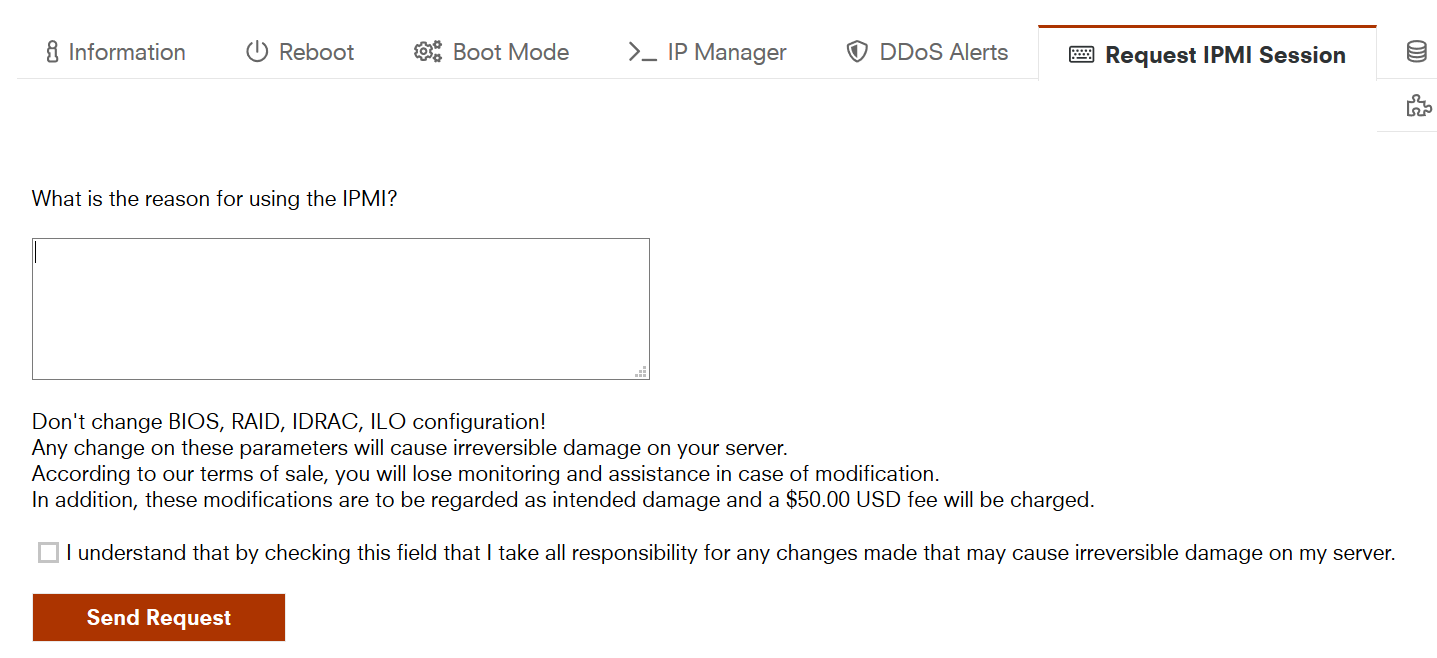 10欧的IPMI写什么申请理由好?
10欧的IPMI写什么申请理由好?
评论 0


Just my socks教程
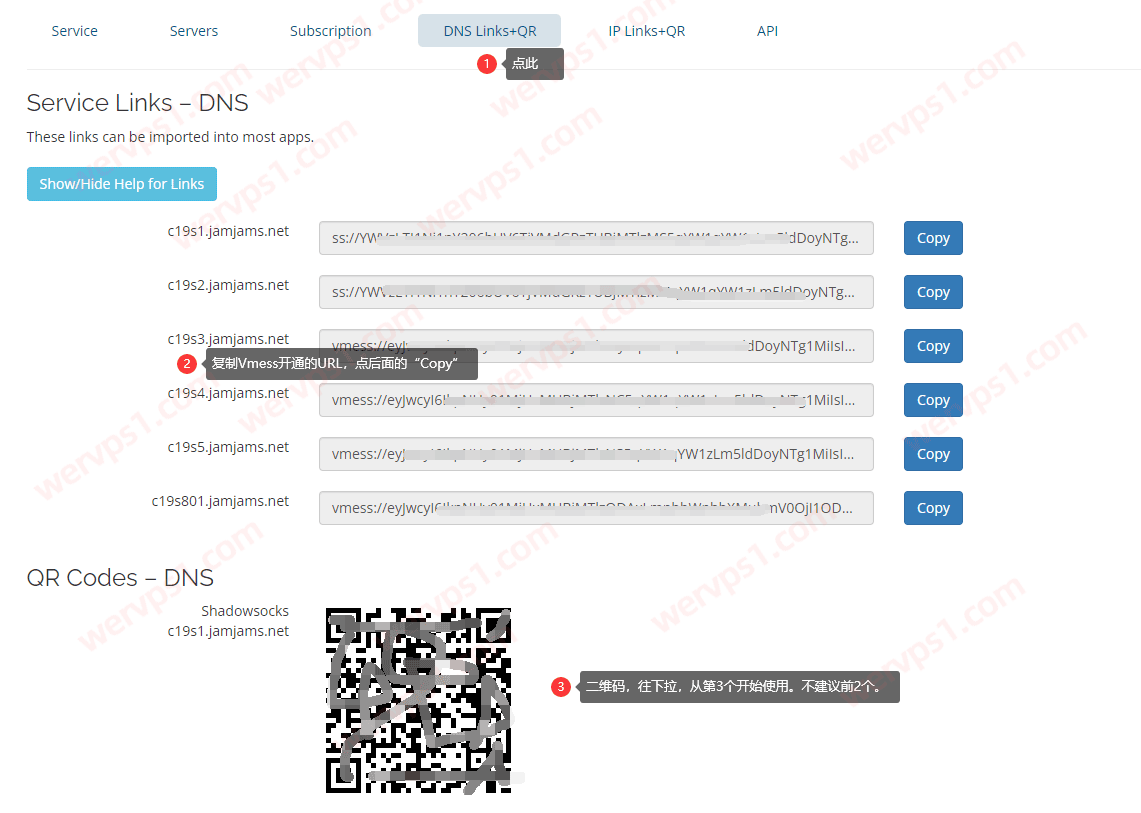
![]() 最新just my socks设置教程:DNS Links+QR(URL导入+二维码)添加阅读(1519)
最新just my socks设置教程:DNS Links+QR(URL导入+二维码)添加阅读(1519) 搬瓦工机场 Just My Socks 购买教程 Just My Socks优惠码/使用方法 Just My Socks Promo code 搬瓦工Shadowsocks购买 可支付宝阅读(48284)
搬瓦工机场 Just My Socks 购买教程 Just My Socks优惠码/使用方法 Just My Socks Promo code 搬瓦工Shadowsocks购买 可支付宝阅读(48284)![]() [更新]:just my socks支持TCP+TLS 可自助更换(小白必看)阅读(1885)
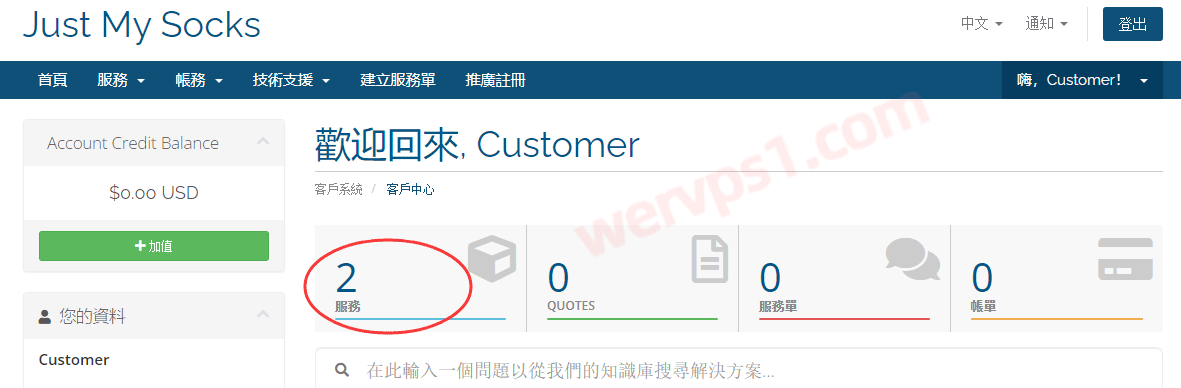
[更新]:just my socks支持TCP+TLS 可自助更换(小白必看)阅读(1885)![]() 新手攻略:Just My Socks购买信息查看和设置教程阅读(2687)
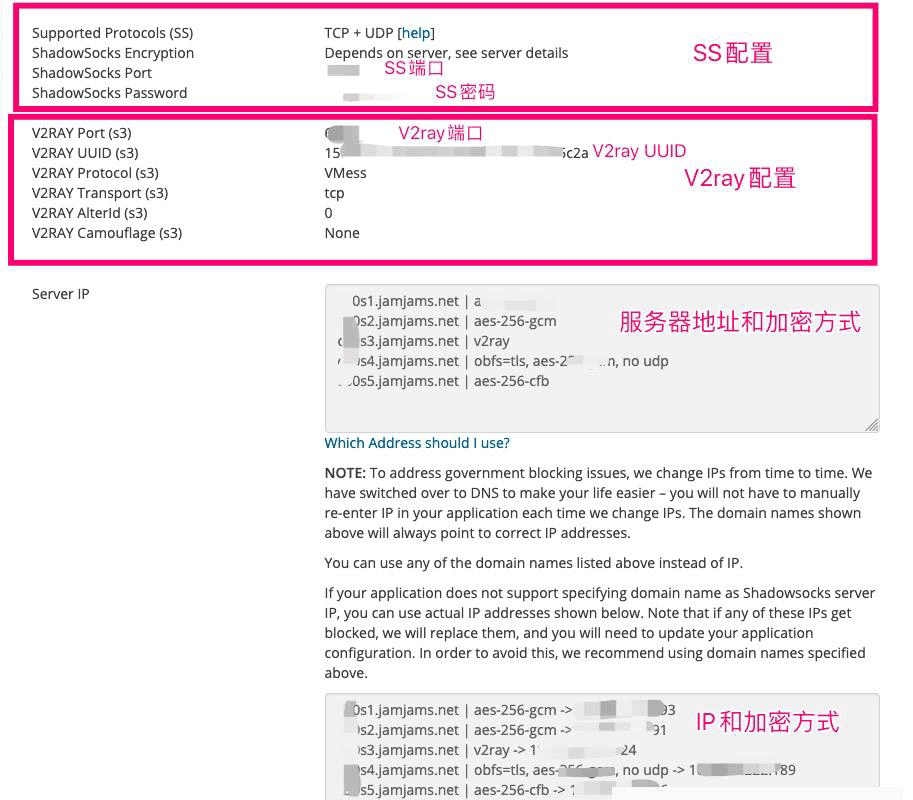
新手攻略:Just My Socks购买信息查看和设置教程阅读(2687)![]() 搬瓦工JMS机场 JustMySocks新增V2ray方式,JMS v2ray设置教程阅读(4663)
搬瓦工JMS机场 JustMySocks新增V2ray方式,JMS v2ray设置教程阅读(4663)![]() just my socks 搬瓦工机场优惠码 +just my socks常见问题阅读(735)
just my socks 搬瓦工机场优惠码 +just my socks常见问题阅读(735)



觉得文章有用就打赏一下文章作者
支付宝扫一扫打赏

微信扫一扫打赏
