美国VPS_搬瓦工CN2 GIA VPS
美国VPS_搬瓦工CN2 GIA VPS
def index_page(self, response):
for each in response.doc(‘a[href^="http"]’).items():
self.crawl(each.attr.href, callback=self.detail_page)
是取回所有链接。如果我想只取回 链接地址里含有bids 这四个字母的链接,该怎么写?
求教了。谢谢!
辽宁网友:
- def index_page(self, response):
- for each in response.doc(‘a[href^="http"]’).items():
- if ‘bids’ in each.attr.href:
- self.crawl(each.attr.href, callback=self.detail_page)
复制代码
四川网友:一楼说的没错,赞一个。
辽宁网友:非常感谢!
未经允许不得转载:美国VPS_搬瓦工CN2 GIA VPS » 有用过pyspider的吗?请教一个小白问题
 腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程
腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程 亏了,刚才退款了一个greencloud日本
亏了,刚才退款了一个greencloud日本
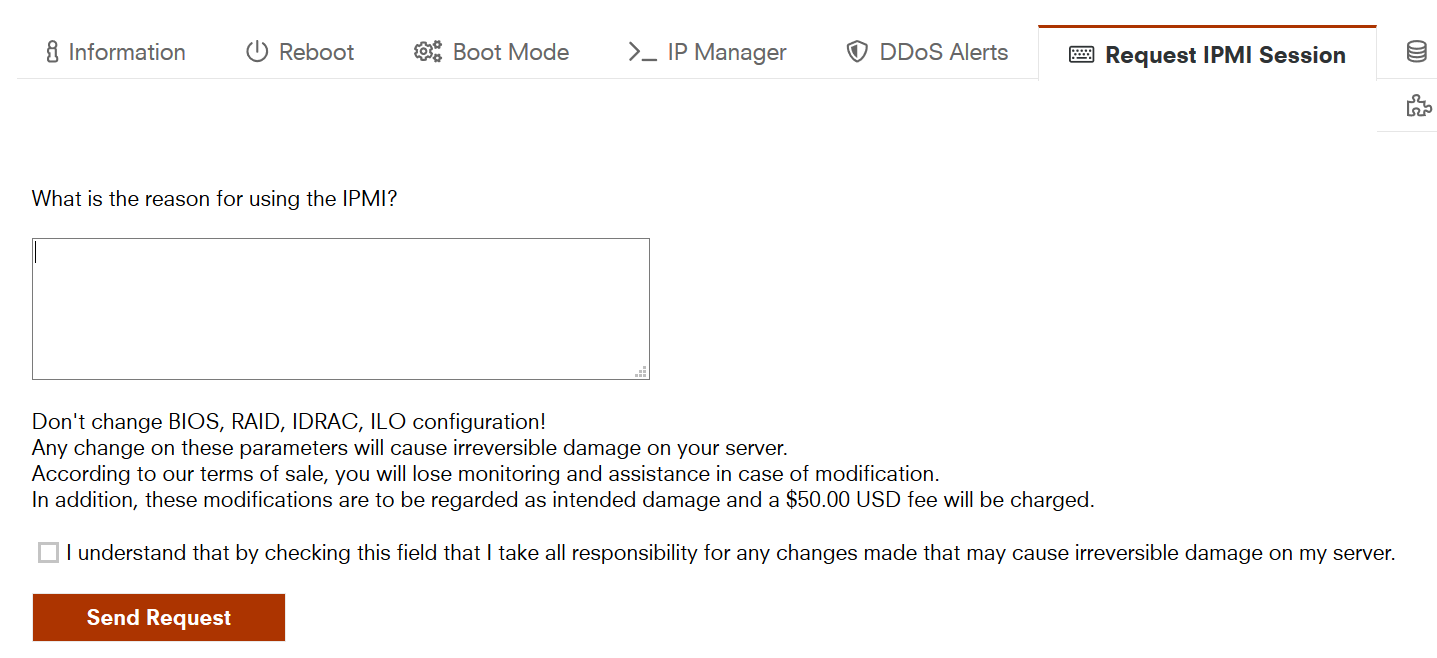 10欧的IPMI写什么申请理由好?
10欧的IPMI写什么申请理由好?