美国VPS_搬瓦工CN2 GIA VPS
美国VPS_搬瓦工CN2 GIA VPS
正在做一个大四的课程设计 目前技术很菜 全靠搜索引擎
主要是想对书签内容进行自动分类什么的
目前实现方法就是爬取页面的全部文字内容 丢到自然语言处理里面跑一跑 分个类 生成tag 返回分类
因为是面对所有页面的的,所以不能直接选对网页元素对象获取。
目前问题是怎么直接获取一个页面的所有文字内容啊?
初步想法是直接对整个页面做个截图,然后OCR就能获取全部内容了。
但这样肯定很耗资源,所以怎样能直接获取文字内容?
我试了替换掉一切html标签 但style标签的内容 一直在 有的时候script的也会去不干净 所以ocr感觉是去的最干净的方法
但这样太暴力了
所以就来找大佬们了!
广西网友:html/text()狗头
湖南网友:这是个啥 js吗还是什么
山西网友:$("button").click(function(){
$("body").text();
});
山西网友:用html解析的那些库啊。例如 https://pythonhosted.org/pyquery/
之后就是html.txt的事
辽宁网友:css选择器
或者直接用正文抽取器,有论文算法的,有也实现好的py/nodejs版的
辽宁网友:如果是指定格式的页面用xpath,如果是不确定格式的页面去github找专门抽取正文的项目,ocr有点那啥了
新疆网友:任何html解析库的都有直接获取`text`的API,如果你不满意,可以自定义。
html是树型结构,获取所有text无外乎遍历所有节点,并转换为文本。
西藏网友:python 或者 php 之类的 做爬虫简单的很
python 直接request 回来之后 用 pyquery 去提取 合适的dom 内的文字;
php 可以用 QueryList
至于 文章情感 和 文章分类, 没必要自己做训练集 ,直接用百度ai开放平台, 又快又稳定 .
再不明白的 可以私信我你的QQ / 微信
宁夏网友:HTMLContentExtractor
网页正文及正文图片提取,基于哈工大的《基于行块分布函数的通用网页正文抽取》算法
https://github.com/miven/HTMLContentExtractor
未经允许不得转载:美国VPS_搬瓦工CN2 GIA VPS » 大佬们请教一个爬虫问题
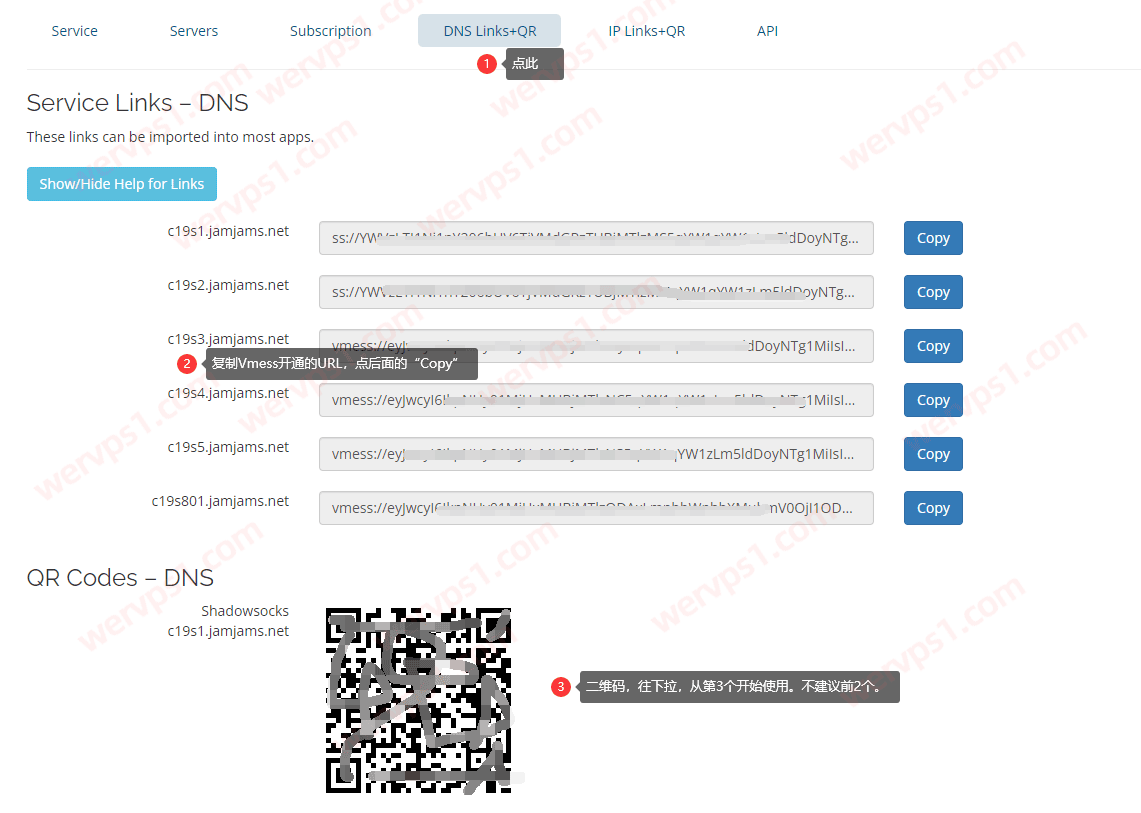
 腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程
腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程 亏了,刚才退款了一个greencloud日本
亏了,刚才退款了一个greencloud日本
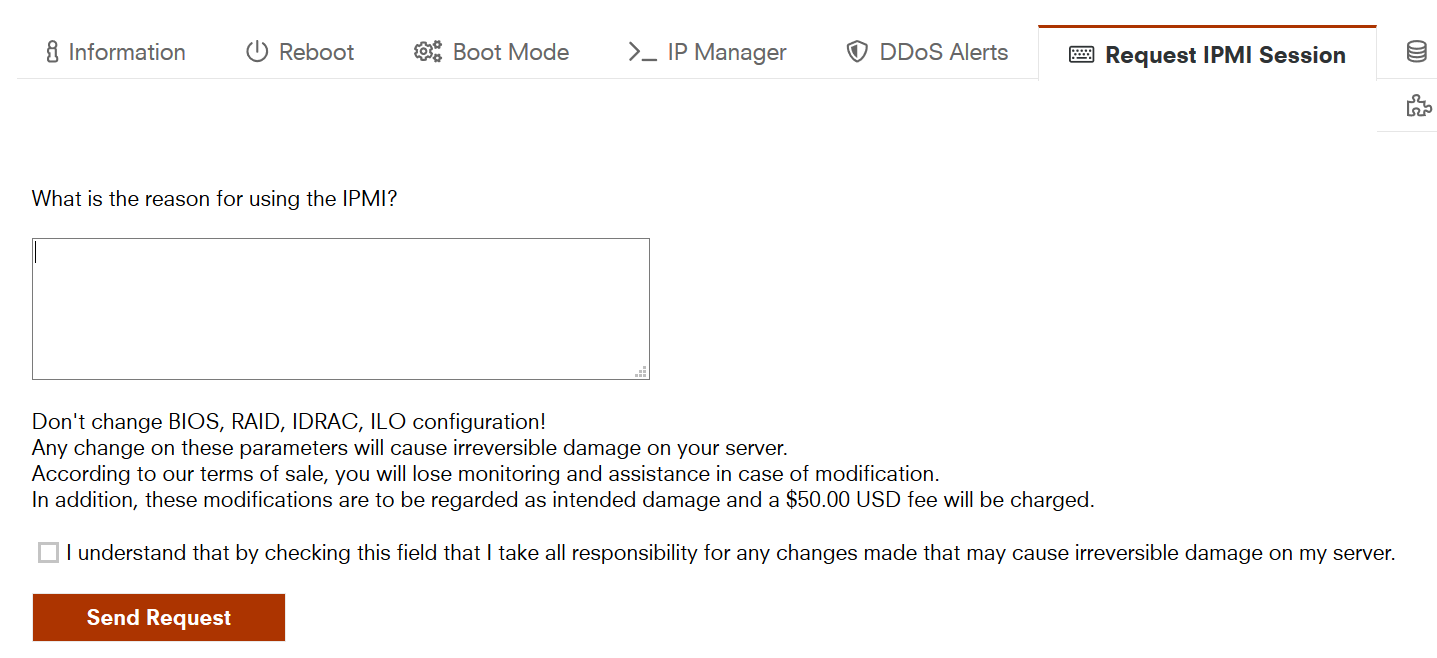 10欧的IPMI写什么申请理由好?
10欧的IPMI写什么申请理由好?