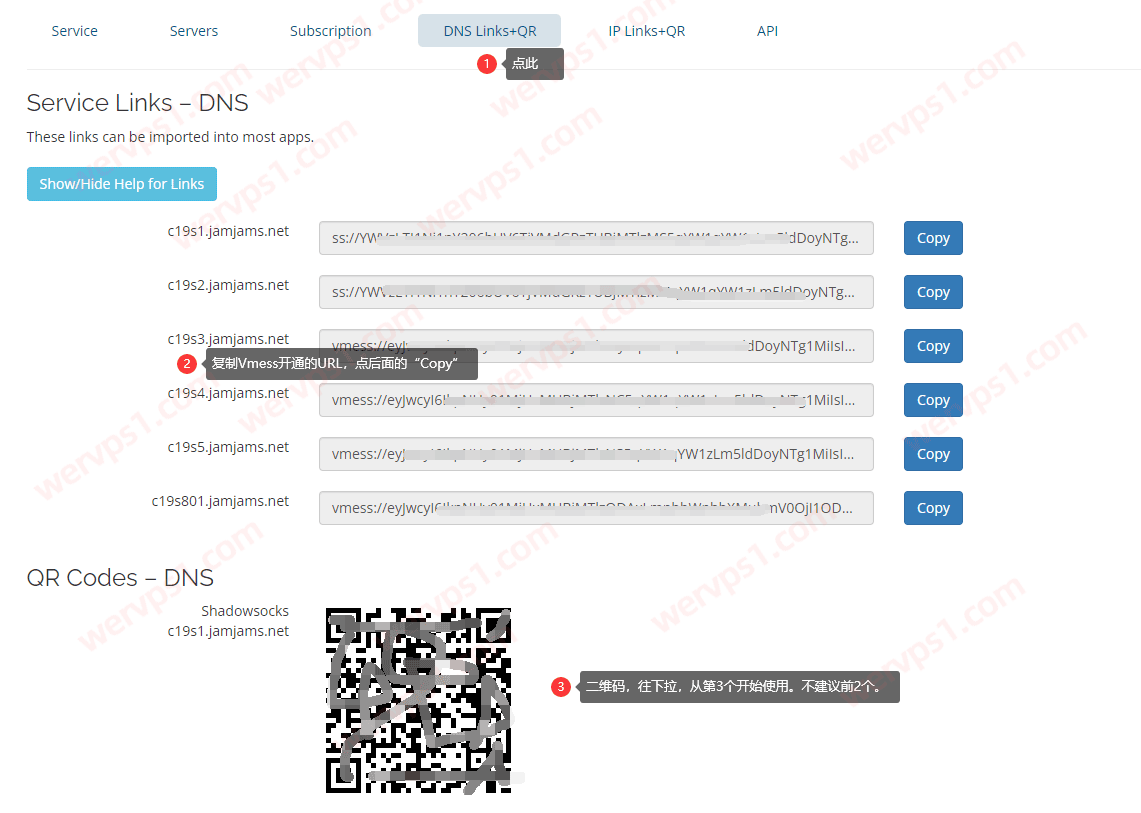
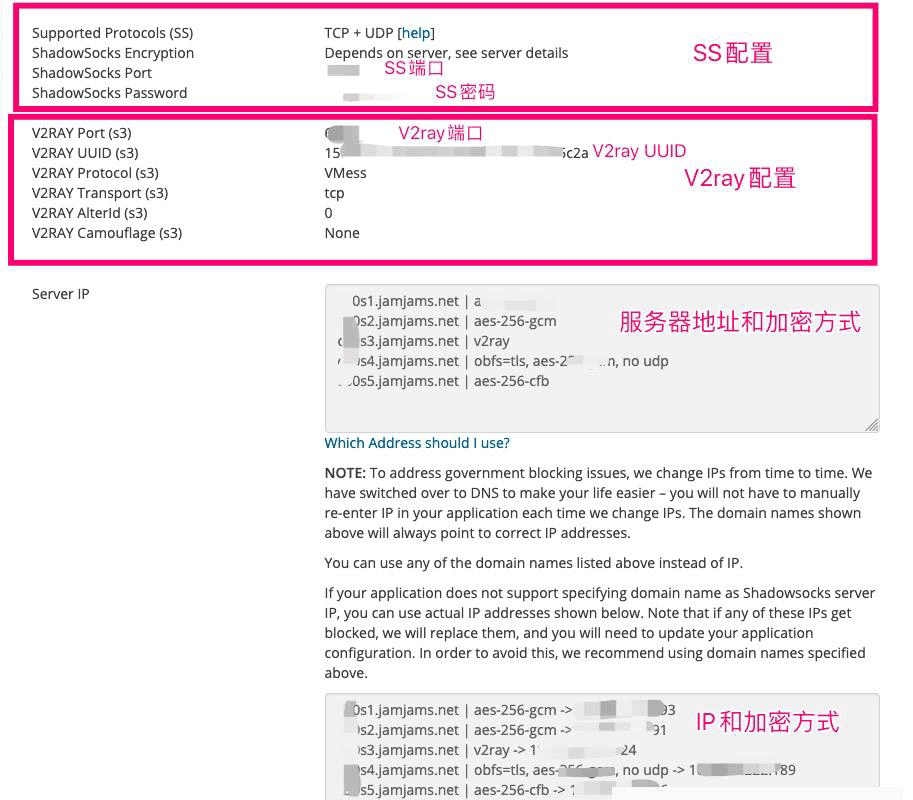
美国VPS_搬瓦工CN2 GIA VPS
美国VPS_搬瓦工CN2 GIA VPS
初中数学
高中数学
线性代数
数学几何
高等数学
离散数学
概率论
数理统计
 求相关视频教程资源。
求相关视频教程资源。
发现要用的时候一个环境扣不上就乱了。
想收集起来慢慢学。
看论文碰到公式就慌神了。解不了公式。。完全没法看下去了。
最近公司鱼不见了,要看一个月监控偷懒写个脚本分析视频图片
看卡尔曼滤波图片匹配处理。。。方程解不下去了。。卡住了要重学。
台湾网友:爱奇艺教育频道
重庆网友:同求啊,大佬找到了分享一下,程序员不学数学有点难受哈哈
黑龙江网友:昨晚在那里补了一下初中的hh208讲的还不错,高中的还没有找到讲的好的
辽宁网友:学不好数学,后期看论文资料根本看不了的说。
河北网友:我也想从头开始学一下的,,,哎,找不到合适的资源
四川网友:看我签名,里面应该有你要的。 域名后天到期了,不准备续费,下载趁早。
海南网友:AC.NZ 这是教育域名啊
广西网友:续费要15$,零花钱都买月饼吃了。
贵州网友:
 腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程
腾讯云轻量怎么购买,云轻量香港/美国/新加坡购买教程 亏了,刚才退款了一个greencloud日本
亏了,刚才退款了一个greencloud日本
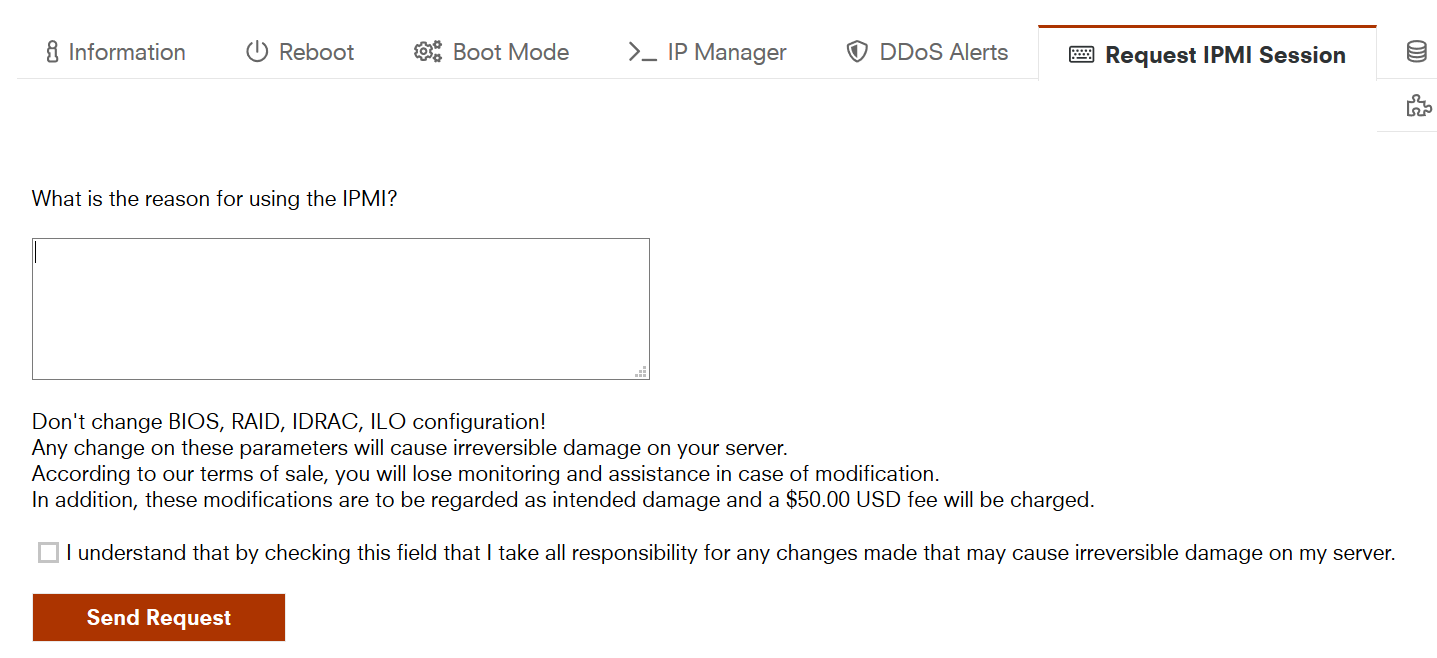 10欧的IPMI写什么申请理由好?
10欧的IPMI写什么申请理由好?